Audio Data Mining
This project was was part of my bachelor studies in Music and Media at Robert-Schumann-Hochschule Düsseldorf.
It was dedicated to the methods for extracting and comparing the fundamental frequencies1, that occur within inconspicuous areas of everyday human interaction.
The data was sourced in a prior project, which aimed to collect variations of human vocal melodies in interjections. This idea was strongly inspired by Conversation Analysis and sociolinguistics2.
After doing some research, I ended up using the package intonation for the R-programming-language to extract and visualize these melodies.
These results would later be needed for other projects
Building on the same audio library, I realised my own version of the AudioTSNEViewer by Machine Learning for Artists:
Visit the tSNE Vocal Sampler and listen to °mm ↓m:°, to get an idea of how to use this data to generate algorithmic scores and synthesize sound.
Todo
There’s a lot still to explore here. The python-script that was used to create the t-SNE plot3 looks for similarities in harmonic content. To apply it to my idea of relative vocal harmony, each sample needs to be put in relation to it’s speakers vocal range. I will soon rewrite it, so that it compares the actual intonation contained in the samples.
Plots and Visualizations
The project will soon be available on GitHub. Meanwhile, you’ll have to settle for some pictures:

Visualization of F0-data through R-intonation, showing the intonation in personalised stylization.

Collection of utterances performed by a good friend, visualized through R-intonation.
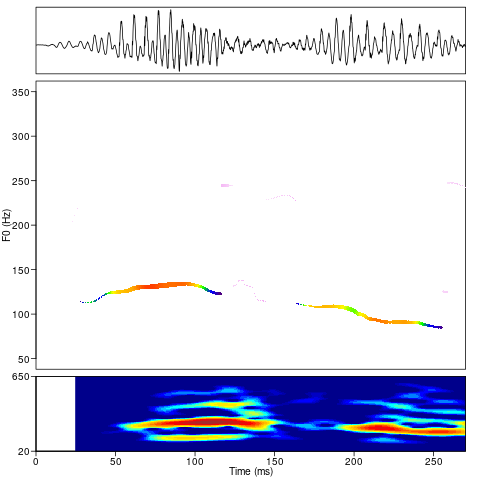
Richvisualization through R-intonation showing waveform, F0-contour and spectrogram in default configuration.